Ollama로 내 맥에서 AI 직접 돌리기 — 설치부터 모델 선택까지 완전 가이드
by SuSu Daddy안녕하세요.
저는 현재 M4 Mac Studio 64GB와 M1 Pro 32GB 두 대를 쓰고 있는데, 어느 순간부터 Claude API 비용이 조금씩 신경 쓰이기 시작했습니다. 코딩 작업이나 문서 정리처럼 굳이 최신 상용 모델이 아니어도 충분한 작업들이 많은데, 그때마다 API를 호출하는 게 낭비처럼 느껴졌거든요.
그래서 로컬에서 LLM을 돌려보기로 했는데, 생각보다 훨씬 쉬웠습니다. Ollama라는 도구 하나로 설치부터 실행까지 10분이면 끝났고, Apple Silicon의 Metal 가속 덕분에 속도도 꽤 만족스럽습니다. 이번 글에서는 제가 직접 세팅하면서 알게 된 내용들을 처음 해보시는 분들도 따라할 수 있도록 최대한 자세히 정리해 보겠습니다.
□ Ollama가 뭔가요
Ollama는 로컬 컴퓨터에서 LLM을 쉽게 실행할 수 있게 해주는 오픈소스 도구입니다. 기존에 로컬에서 AI 모델을 돌리려면 Python 환경 세팅, CUDA 드라이버, 모델 가중치 변환 같은 복잡한 과정이 필요했는데, Ollama는 이 모든 걸 ollama run 모델명 명령 하나로 해결해 줍니다.
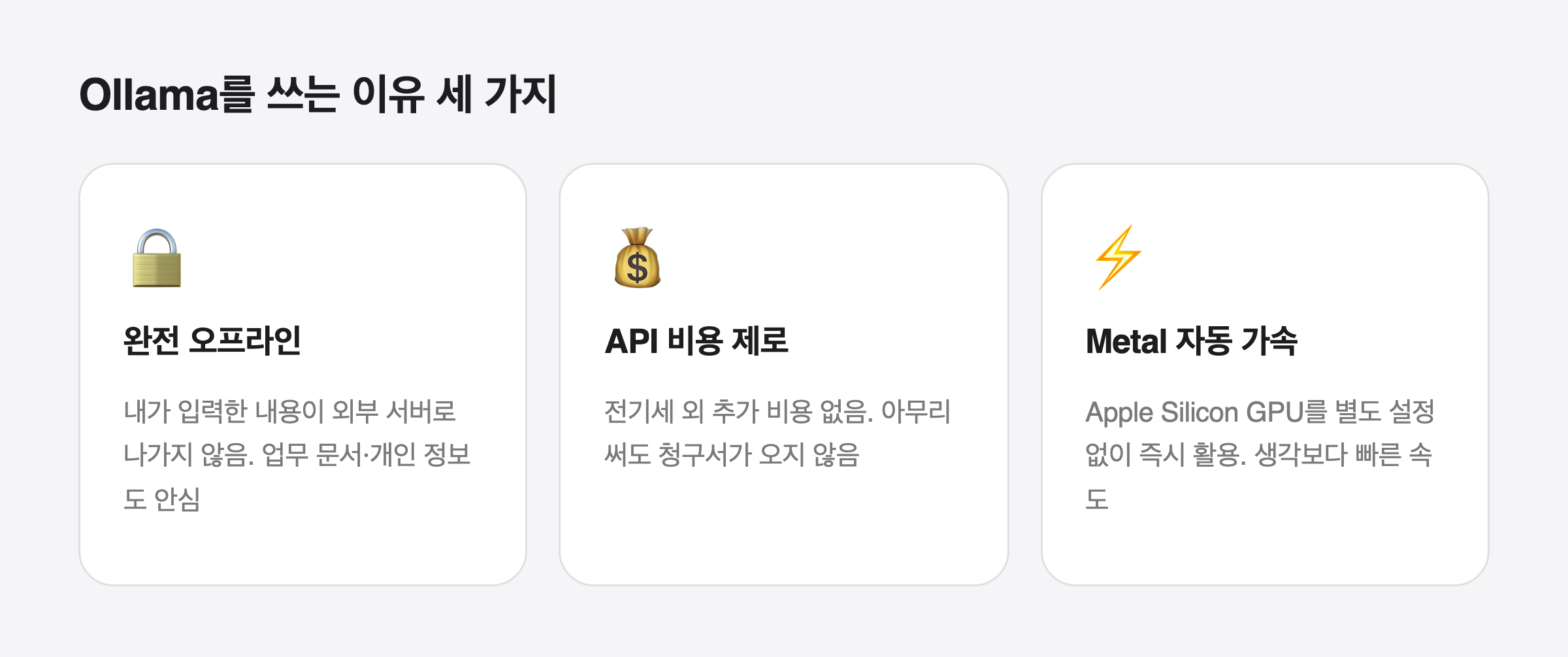
무엇보다 좋은 점은 세 가지입니다.
첫째, 완전히 오프라인에서 동작합니다. 인터넷 연결 없이도 쓸 수 있고, 내가 입력한 텍스트가 외부 서버로 나가지 않습니다. 민감한 업무 문서나 개인 정보를 다룰 때 마음이 편합니다.
둘째, API 비용이 없습니다. 전기세 빼면 추가 비용이 전혀 없습니다.
셋째, Apple Silicon에서 Metal 가속이 자동으로 적용됩니다. 별도 설정 없이 GPU를 활용하기 때문에 생각보다 빠른 속도가 나옵니다.
□ 내 맥이 어떤 모델을 돌릴 수 있을까
Ollama에서 모델을 고를 때 가장 중요한 건 RAM 용량입니다. 모델을 RAM에 통째로 올려서 실행하기 때문에, 모델 크기보다 여유 있는 RAM이 있어야 쾌적하게 사용할 수 있습니다.
Apple Silicon은 CPU와 GPU가 메모리를 공유하는 통합 메모리(Unified Memory) 구조라서, 같은 용량이라도 NVIDIA GPU가 달린 PC보다 훨씬 효율적으로 모델을 돌릴 수 있습니다.
아래 기준을 참고하시면 됩니다.
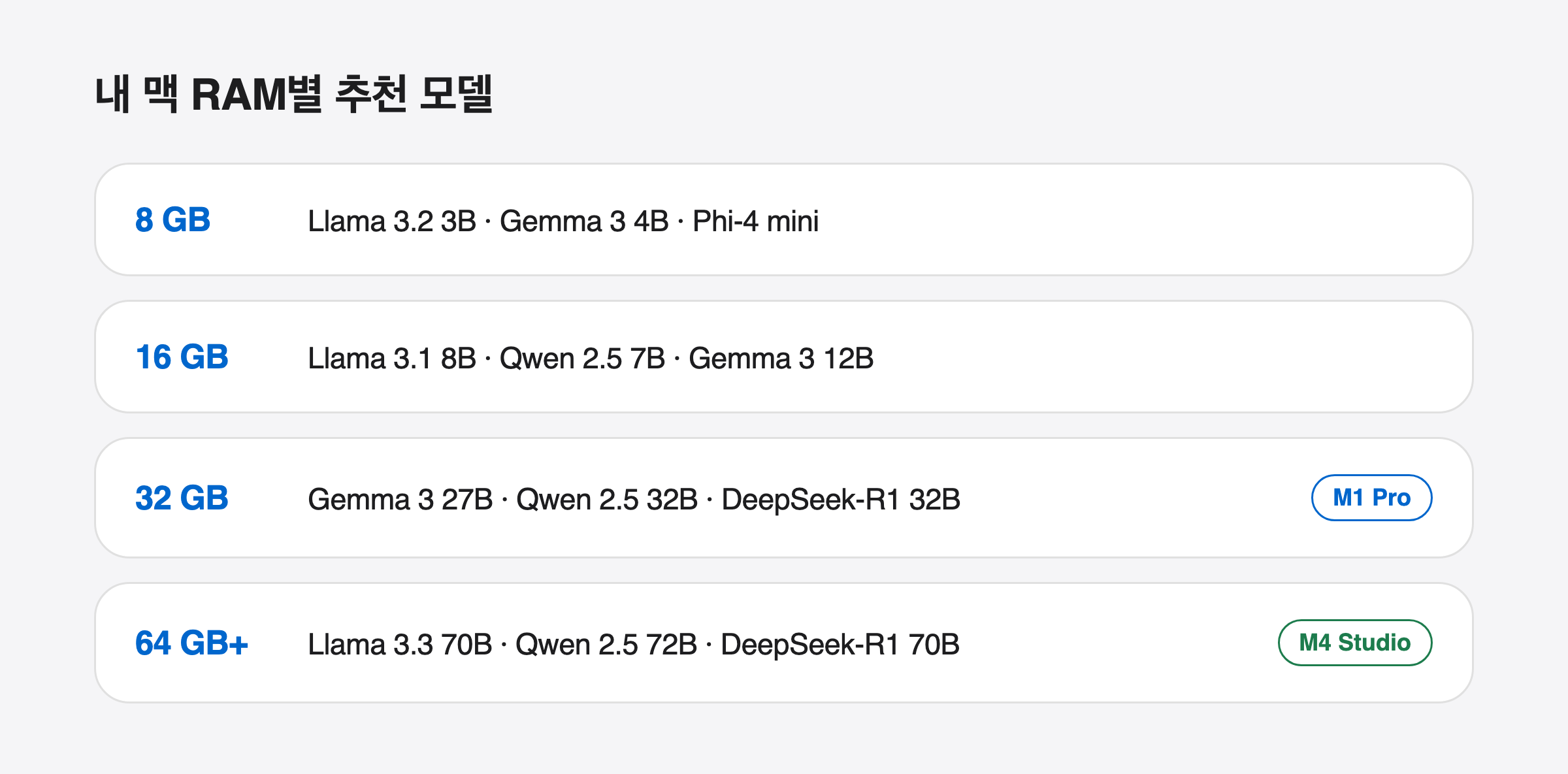
- 8GB: Llama 3.2 3B, Gemma 3 4B, Phi-4 mini 등 경량 모델 → 간단한 대화, 요약 용도
- 16GB: Llama 3.1 8B, Gemma 3 12B, Qwen 2.5 7B → 일반 작업에 충분한 품질
- 32GB: Gemma 3 27B, Qwen 2.5 32B, DeepSeek-R1 32B → 코딩·분석 실용 수준
- 64GB 이상: Llama 3.3 70B, Qwen 2.5 72B, DeepSeek-R1 70B → 상용 API에 근접한 품질
저는 M1 Pro 32GB에서 Gemma 3 27B와 Qwen 2.5 32B를 주로 쓰는데, 코드 리뷰나 문서 정리 정도는 Claude Sonnet과 크게 차이를 못 느낄 정도입니다. M4 Mac Studio 64GB에서는 Llama 3.3 70B도 무리 없이 돌아가고, 토큰 생성 속도도 초당 20토큰 이상 나옵니다.
□ 설치 방법
사전 조건: macOS 13 이상, Homebrew 설치 권장
방법 1 — 공식 사이트에서 앱 설치 (가장 간단)
ollama.com에 접속해서 Download 버튼을 누르면 macOS용 .dmg 파일을 받을 수 있습니다. 설치 후 메뉴바에 라마 아이콘이 생기면 준비된 겁니다.
방법 2 — Homebrew로 설치
터미널을 열고 아래 명령어를 입력합니다.
brew install ollama설치 확인:
ollama --version버전 번호가 출력되면 설치 완료입니다.
서비스 시작:
Homebrew로 설치한 경우 아래 명령어로 백그라운드 서비스를 실행합니다.
brew services start ollama앱으로 설치했다면 앱을 실행하기만 하면 자동으로 서비스가 시작됩니다.
Linux / Windows:
Linux는 아래 한 줄이면 됩니다.
curl -fsSL https://ollama.com/install.sh | shWindows는 공식 사이트에서 .exe 설치 파일을 받아서 실행하면 됩니다.
□ 첫 번째 모델 실행해보기
설치가 됐으면 이제 모델을 받아서 실행해 볼 차례입니다. 터미널을 열고 아래 명령어를 입력해 보세요.
ollama run gemma3:4b처음 실행하면 모델 파일을 자동으로 다운로드합니다. Gemma 3 4B 기준으로 약 3GB 정도 받습니다. 다운이 끝나면 바로 대화창이 열립니다.
>>> 안녕하세요, 간단하게 자기소개 해줘
저는 Gemma입니다. Google DeepMind가 개발한 AI 언어 모델이에요...대화창에서 나가려면 /bye를 입력하거나 Ctrl+D를 누르면 됩니다.
한 번만 질문하고 바로 결과 받기:
ollama run gemma3:4b "파이썬에서 리스트 컴프리헨션 예시 3개 보여줘"터미널에서 파이프로 연결할 수도 있습니다.
cat 코드.py | ollama run qwen2.5-coder:7b "이 코드 리뷰해줘"
□ RAM별 추천 모델 목록
모델을 고를 때 헷갈리는 분들을 위해 제가 직접 써본 것 위주로 정리했습니다.
8~16GB 맥 (MacBook Air, 기본형 MacBook Pro):
ollama run llama3.2:3b # 가볍고 빠름, 일상 대화용
ollama run gemma3:4b # 한국어 이해력 괜찮음
ollama run phi4-mini # Microsoft 모델, 4GB 경량
ollama run qwen2.5:7b # 한국어·다국어 가장 강함32GB 맥 (M1/M2/M3 Pro, M1/M2 Max):
ollama run gemma3:27b # 제가 M1 Pro에서 메인으로 쓰는 모델
ollama run qwen2.5:32b # 코딩·분석에 강함
ollama run deepseek-r1:32b # 수학·추론 특화, 생각 과정 보여줌
ollama run qwen2.5-coder:32b # 코딩 전용64GB 이상 (M2/M3/M4 Ultra, M4 Max):
ollama run llama3.3:70b # M4 Mac Studio에서 메인으로 씀
ollama run qwen2.5:72b # 다국어 72B, 한국어도 훌륭
ollama run deepseek-r1:70b # 추론 특화 70B한국어 처리 성능은 Qwen 계열이 가장 우수합니다. 중국 알리바바가 만든 모델인데, 아시아권 언어 데이터가 많이 포함되어 있어서 한국어 답변 품질이 확연히 다릅니다. 일상 대화나 문서 작업은 Qwen을, 영어 코딩 작업은 Llama나 DeepSeek-Coder를 추천드립니다.
□ 자주 쓰는 명령어 정리
# 설치된 모델 목록 보기
ollama list
# 모델 다운로드만 하기 (실행 안 함)
ollama pull llama3.3:70b
# 모델 실행
ollama run qwen2.5:32b
# 모델 정보 보기 (파라미터 수, 컨텍스트 길이 등)
ollama show qwen2.5:32b
# 실행 중인 모델 확인
ollama ps
# 모델 삭제 (용량 확보)
ollama rm llama3.2:3b
# Ollama 서버 직접 실행 (백그라운드 서비스 아닌 경우)
ollama serve
□ Open WebUI — ChatGPT처럼 쓰기
터미널 대화가 불편하다면 Open WebUI를 설치하면 ChatGPT랑 거의 똑같은 웹 인터페이스를 로컬에서 사용할 수 있습니다. 대화 기록도 저장되고, 여러 모델을 골라가며 쓸 수 있습니다.
Docker가 설치되어 있다면 아래 명령어 하나로 실행됩니다.
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main실행 후 브라우저에서 http://localhost:3000으로 접속하면 됩니다. 처음 접속 시 계정을 만들라고 하는데, 로컬 전용이라 아무 이메일이나 입력해도 됩니다.
Ollama와 연동이 자동으로 되기 때문에 ollama pull로 받아놓은 모델들이 드롭다운에 그대로 뜹니다.

□ 터미널에서 더 편리하게 — alias 설정
매번 ollama run qwen2.5:32b 치기 귀찮으니 ~/.zshrc에 단축 명령어를 등록해 두면 편합니다.
# ~/.zshrc 에 추가
alias ai="ollama run qwen2.5:32b"
alias ai-fast="ollama run gemma3:4b"
alias ai-code="ollama run qwen2.5-coder:32b"
alias ai-think="ollama run deepseek-r1:32b"저장 후 적용:
source ~/.zshrc이제 터미널에서 ai "질문" 형태로 바로 쓸 수 있습니다.
ai "이 함수 시간복잡도 분석해줘"
ai-code "TypeScript 타입 오류 고쳐줘"
ai-think "이 수학 문제 풀어줘"파일 내용을 직접 넘겨서 분석하는 것도 됩니다.
cat README.md | ai "이 문서 한 줄 요약해줘"
cat 코드.ts | ai-code "버그 찾아줘"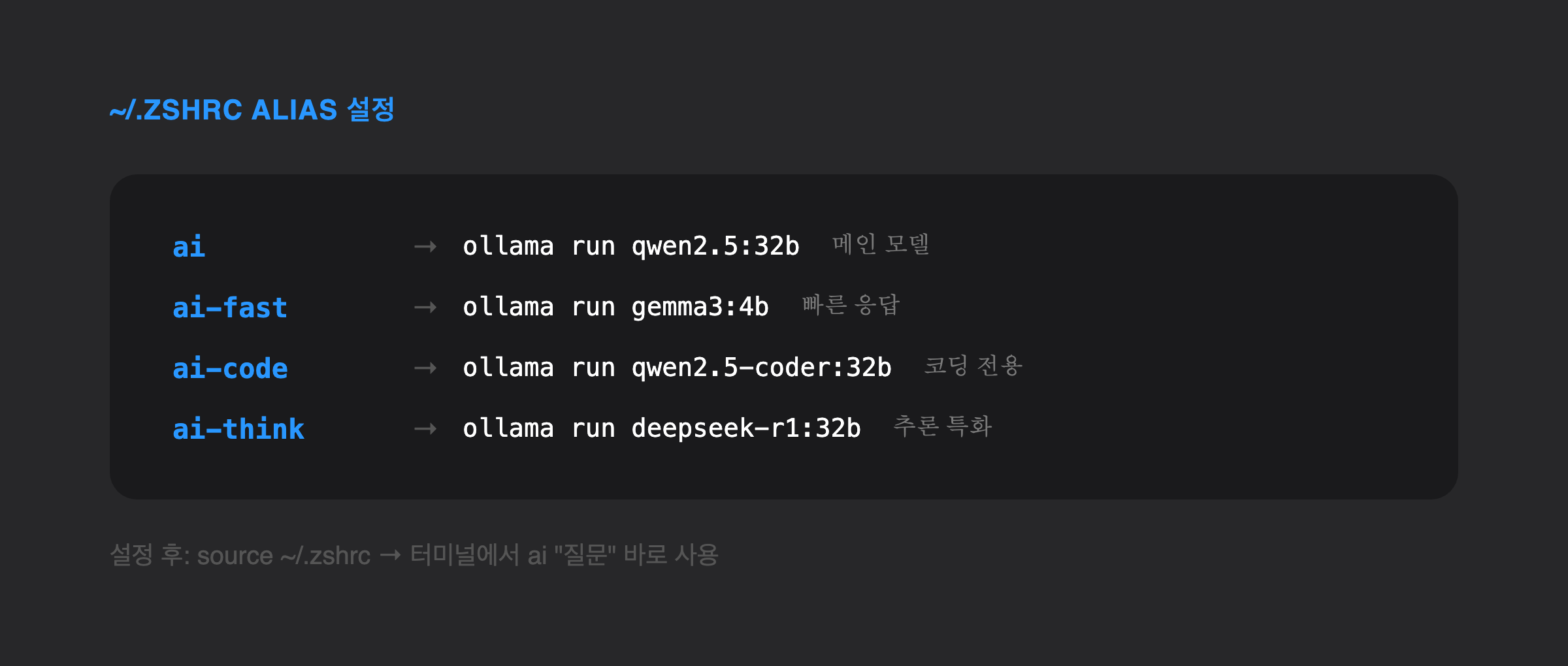
□ 자주 겪는 문제와 해결법
모델이 느릴 때:
RAM 용량에 비해 너무 큰 모델을 실행하면 스왑을 사용해 속도가 급격히 떨어집니다. ollama ps로 현재 실행 중인 모델을 확인하고, 하나씩만 올려두는 게 좋습니다.
ollama ps # 현재 메모리에 올라간 모델 확인포트 충돌이 날 때:
Ollama는 기본으로 11434 포트를 사용합니다. 다른 서비스와 충돌한다면 환경 변수로 변경할 수 있습니다.
OLLAMA_HOST=0.0.0.0:11435 ollama serve모델 저장 위치:
다운로드한 모델은 ~/.ollama/models/ 에 저장됩니다. 용량이 부족할 때 여기서 직접 삭제하거나 ollama rm 모델명으로 지우면 됩니다.
du -sh ~/.ollama/models/ # 전체 모델 용량 확인
ollama list # 모델 목록
ollama rm qwen2.5:72b # 특정 모델 삭제
□ 마무리
솔직히 말하면 로컬 모델이 Claude나 GPT-4를 완전히 대체하기는 어렵습니다. 복잡한 추론이나 최신 정보가 필요한 작업은 여전히 상용 API가 낫습니다.
하지만 코드 리뷰, 문서 초안 작성, 간단한 번역, 데이터 정리처럼 반복적으로 하는 작업들은 32B 이상 모델로도 충분히 커버가 됩니다. 특히 개인 파일이나 업무 문서를 다룰 때 클라우드에 데이터를 보내지 않아도 된다는 게 생각보다 큰 장점이더라고요.
M1 Pro 32GB에서 Qwen 2.5 32B로 문서 정리를 해보면서 "이 정도면 충분하겠다"는 생각이 들었습니다. 64GB Mac Studio에서 70B 모델 돌리는 건 그냥 재미로 해본 수준이지만, 실제로 속도도 놀라울 정도로 빠릅니다.
16GB 이상 맥이 있다면 한 번 설치해 보시는 것을 추천드립니다. 설치에 5분, 첫 모델 다운로드에 몇 분이면 바로 쓸 수 있습니다.
감사합니다.
'AI' 카테고리의 다른 글
| Claude Pro 만료 후 Codex Plus 한달 비교 (0) | 2026.06.18 |
|---|
블로그의 정보
SuSu Daddy
SuSu Daddy